What AI Actually Is
The previous two articles built up a chain. The first ran from Aristotle’s two-valued logic through Leibniz, Boole, Gauss, and Shannon to the bit as a unit of information. The second ran from Hilbert’s decision problem through Turing, the Universal Approximation Theorem, and Banach’s convergence guarantee to the modern neural network. This article asks what to make of all of it: what is the thing we are actually calling AI, and where does it leave the human?
I want to start with something I find useful to keep in front of me, because it clarifies almost every confused conversation about AI I have ever had.
Blackboxes and the Manual Way
Think of a real-world function as a black box. Something goes in, something comes out, according to some rule. The box does not care what you think is inside it. It just maps inputs to outputs.
For some boxes, a smart mathematician can look at enough input-output pairs and see the rule directly. A physicist measuring voltage and current recognises Ohm’s law. A structural engineer sees a force-displacement relationship and fits a spring constant. A clever programmer can then take that formula and implement it efficiently. Add a physicist who understands how to translate a physical measurement into a digital signal, and a mechatroniker who knows how to turn a bit pattern into a motor command, and you have the ingredients for a functional intelligent robot. Each person contributes one piece of the chain from world to decision to action.
This is not a hypothetical. It is how most of the automation we rely on was actually built: by people who understood the domain, identified the relevant variables, wrote down the relationship, and implemented it. The intelligence was human, the execution was mechanical.
The problem is that some boxes resist this approach. Human language is one of them. The rule that maps a sentence to its appropriate response is not one that any mathematician has written down, because it is not a formula at all. It is an enormously complex, context-dependent, culturally embedded mapping that took hundreds of thousands of years of human evolution and social practice to produce. Nobody can inspect it and extract an equation. The manual way breaks down.
What Training Actually Does
When the manual way breaks down, the question becomes: can we replace the mathematician with a computer program? Can we feed the machine a large list of input-output pairs, and have it figure out what the mapping looks like, and then produce a second program that implements that mapping well enough to be useful?
This is what training does. It is the automation of the step the mathematician used to perform by hand. You define a family of possible functions (your neural network architecture, which the UAT tells you is expressive enough to approximate almost anything). You collect data: pairs of inputs and desired outputs. You run a training procedure that searches through that family for the member that fits the data best, in the sense of minimising a chosen error measure. When the procedure converges, you have a model: a fixed, deterministic function, with its parameters set.
That model is a program. It is data: a long sequence of numbers stored in memory. When you run it, you are evaluating a function. Input goes in, output comes out. The schema from the previous article applies directly: DATA (your prompt) + DATA (the model weights) gives you TRANSFORMATION (the forward pass through the network) gives you DATA (the response).
Nothing in that process, at inference time, is learning, deciding, or thinking. It is matrix multiplication. The same input always produces the same output. A language model answering your question is no more “intelligent” at that moment than a sorted list is intelligent for being sorted.
The Training Process Is the AI. The Model Is Not.
This is the distinction I want to press on, because I think almost all confusion about AI collapses once you hold it clearly.
The intelligence, if we want to use that word at all, is in the training process. It is in the choice of architecture, the choice of loss function, the collection and curation of training data, the engineering of the optimiser, and the infrastructure that runs billions of parameter updates until the loss converges. That process searched through an astronomically large space of possible functions and found one that approximates the target mapping well enough to be useful. That search is remarkable. That is where the interesting thing happened.
The running model is the result of that search. It is a certificate, not a process. Ada Lovelace wrote, in 1843, that the Analytical Engine “can do whatever we know how to order it to perform.” She meant it as a limitation. Re-read in the light of training: the model can do whatever the training process knew how to encode into it. The training process, not the model, is the locus of whatever deserves the name intelligence.
Language as Lossy Quantisation
With that distinction in place, I want to work through six ideas about what language is and what it means for both human and machine intelligence. These matter because the thing we are mostly using as the interface to AI systems right now is language, and language has properties that cut directly into the question of what a trained model can and cannot do.
Words are case distinctions, not the thing itself. The word “cat” does not contain a cat. It is a pointer, agreed upon by convention, that picks out a region of conceptual space. “Cat”, “Katze”, “gato”, and “猫” (mao) all point to the same region via different pointers. At the level of the letter sequence as a number (you can read any word as a base-26 integer), they are completely different. At the level of meaning, they are identical. This two-layer structure, symbol system on top, meaning system underneath, is not an accident. It is how language works. A model trained on text learns the statistical regularities of the symbol layer. Whether it reaches the meaning layer is a genuine open question.
Some descriptions are lossless, most are not. The numeral “3” (or “0b11” in binary, or “III” in Roman notation) describes a precise, discrete state with no ambiguity. The word “warm” does not. It carves a continuous temperature axis into a rough category, losing almost all information about the specific temperature involved. Most of human language is like “warm”, not like “3”. It is a lossy compression of experience into categories coarse enough to be spoken and heard in real time.
Language is a solution to an engineering problem. Shannon’s rate-distortion theory says you cannot simultaneously minimise the information lost in a description and the length of that description. You always trade one for the other. Natural language sits at a particular point on that curve: short enough to be spoken in real time by a breathing, forgetting, interrupted speaker; lossy enough to leave the hard work of disambiguation to context and shared knowledge. Zipf’s law, the observation that the most common words are the shortest, is this trade-off self-organising. Language did not arrive at this point by design. It was selected for, over thousands of generations, because speakers who found the right trade-off communicated better. Shannon described the law. Evolution found the solution.
Fixing the channel does not fix the loss. Suppose you had a perfect voice and a perfect ear: a lossless acoustic channel. Would that give you lossless communication? No. The bottleneck is not the channel. It is the encoding. Before any word leaves your mouth, you have already mapped a continuous, private experience onto a discrete, shared symbol. That mapping discards almost everything. Transmitting “I am in pain” with perfect fidelity still does not transfer the experience of pain. The loss happened when you chose the word, not when you spoke it.
The infinite is nobody’s territory. If reality is genuinely continuous and unbounded, then both humans and machines are finite quantisers working on the same infinitely large problem. The human does not have special access to the unquantised real. The human’s quantisation vocabulary is tuned by evolution to bodies, survival, and social life. The machine’s quantisation vocabulary is inherited from ours, since it trained on our text. It is a quantiser of our quantisation: a second-order approximation. Whether that is a limitation or merely a different kind of approximation is a question worth sitting with.
The spaces are complementary, not identical. The overlap between what a human can express and what a model has encoded is large, because the model trained on human expression. But the overlap is not total. The human brings a body, a history, a position in time, mortality, and the knowledge that comes from having stakes in the outcome. The model brings the entire written corpus processed simultaneously, exact pattern recall across billions of tokens, and no fatigue. These are not the same set of capabilities with one being larger. They are different shapes, sharing a large common region but each extending into territory the other does not reach.
Interpolation, Extrapolation, and Hallucination
All of that has a concrete consequence for what a trained model can and cannot do, and it is best understood geometrically.
Imagine you have three points in a coordinate system and you want to find the function that passes through them. With three points, a parabola fits perfectly. The residuals are zero. Everything looks clean. If someone asks you for the value of the function between those three points, you interpolate: you read off the parabola’s value, and provided the true underlying function really is a parabola, you will be right.
Now add a fourth point, well outside the range of the first three. The parabola, fitted on the original three, will not pass through it. The squared error at the new point may be very large. The correct model, it turns out, is a cubic polynomial. But you could not have known that from three points alone. Three points underdetermined the model family.
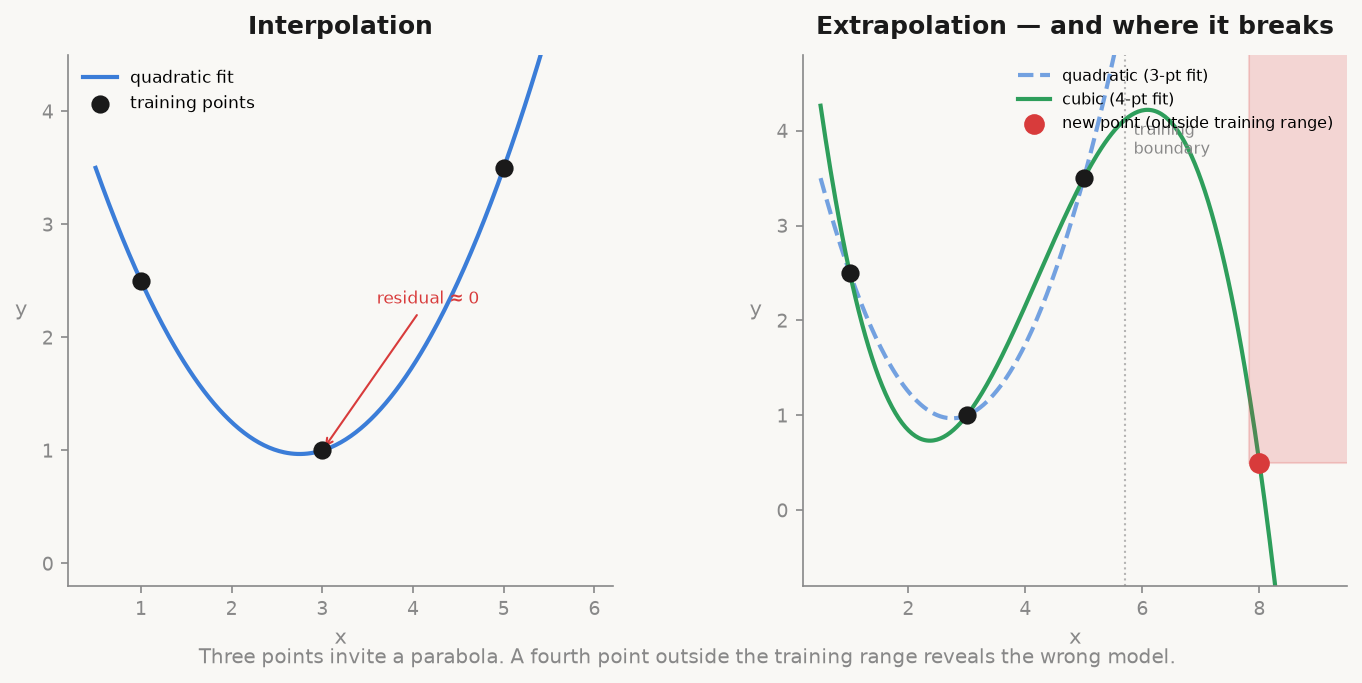
A language model’s training data is a set of points. The model is the function fitted to them. Within the distribution of that training data (the interpolation regime), the model performs remarkably well. It has seen enough examples of similar inputs and outputs that its approximation is accurate.
Outside that distribution (the extrapolation regime), the fitted function is being evaluated in a region where it has no data to constrain it. It will produce an output, because it is a function and functions always produce outputs. But there is no guarantee that output bears any relationship to the correct answer. This is what hallucination is. It is not a bug or a sign of deception. It is the model doing exactly what it was trained to do (produce plausible continuations of text) in a region where plausibility is no longer anchored by data. The parabola, extrapolated far enough, gives you confidently wrong numbers. The model, extrapolated far enough, gives you confidently wrong facts.
The lesson is not that models are useless outside their training distribution. It is that you need to know which regime you are in. Inside the training distribution, trust the interpolation. Outside it, verify.
The Human Niche and the Divine Spark
This brings me to the question I find most interesting: where does the human advantage persist?
The model interpolates. It does so at remarkable scale and speed, over a training distribution that covers most of recorded human knowledge. For tasks that live inside that distribution, the model will often match or exceed human performance, simply because it has seen more examples and recalls them more exactly.
But creative work, in the deepest sense, is extrapolation. It is the production of something that does not yet exist in the training data, that cannot be reached by interpolation from known points, that requires the generation of a new point in a space where the model has no data to fit. The model can produce text that looks creative because it recombines familiar patterns in unfamiliar ways. That is impressive, and useful, and not nothing. But it is not the same as genuinely extending the frontier.
I am cautious about making this argument too quickly, because the boundary between recombination and genuine novelty is genuinely hard to draw. But I think there is something real here, and I want to name it: the human ability to stand at the edge of the known, feel the discomfort of genuine uncertainty, and commit to a direction anyway, is not well-modelled by a function that returns the statistically most plausible next token. The mathematician who saw a pattern nobody had seen before was not interpolating. The physicist who proposed a model that contradicted all prior experiments was not interpolating. The artist who made something that had no precedent was not interpolating.
I discussed the question of whether any of this is connected to consciousness in an earlier piece on machine consciousness, and I do not want to repeat that argument here. But I will say this: the tradition that speaks of a divine spark in the human, the capacity for genuine creation that does not merely recombine what came before, points at something that the interpolation picture of intelligence does not capture. Whether that capacity is consciousness, or something else, or whether machines will eventually acquire it, I do not know. What I do think is that it is precisely this capacity that defines the domain where human intelligence has something the trained model structurally lacks: not more data, not faster recall, but the ability to generate a genuinely new point in a space where no training data exists.
The model trained on everything humans have written is a mirror of what we have already said. The next thing worth saying is, by definition, not yet in the mirror.
Image sources
- Fig. 1: Interpolation vs. extrapolation. Illustration by the author. Generated with matplotlib/Python.
These three articles form a connected arc: from the bit, to the function, to the question of what the function cannot do. If you want to follow any of these threads further, the Discord is the best place.
If you want to talk through any of this, come find us on Discord.